Method
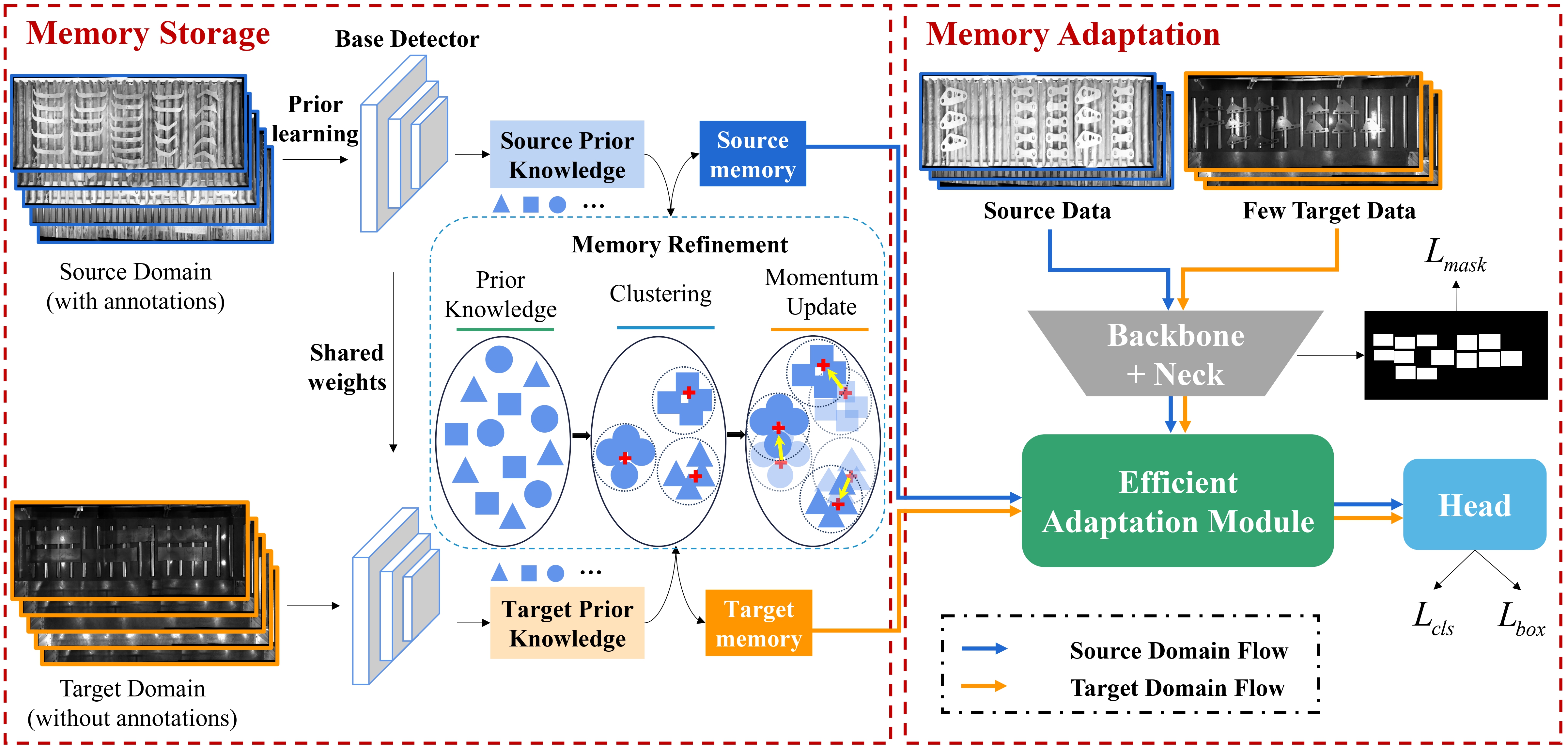
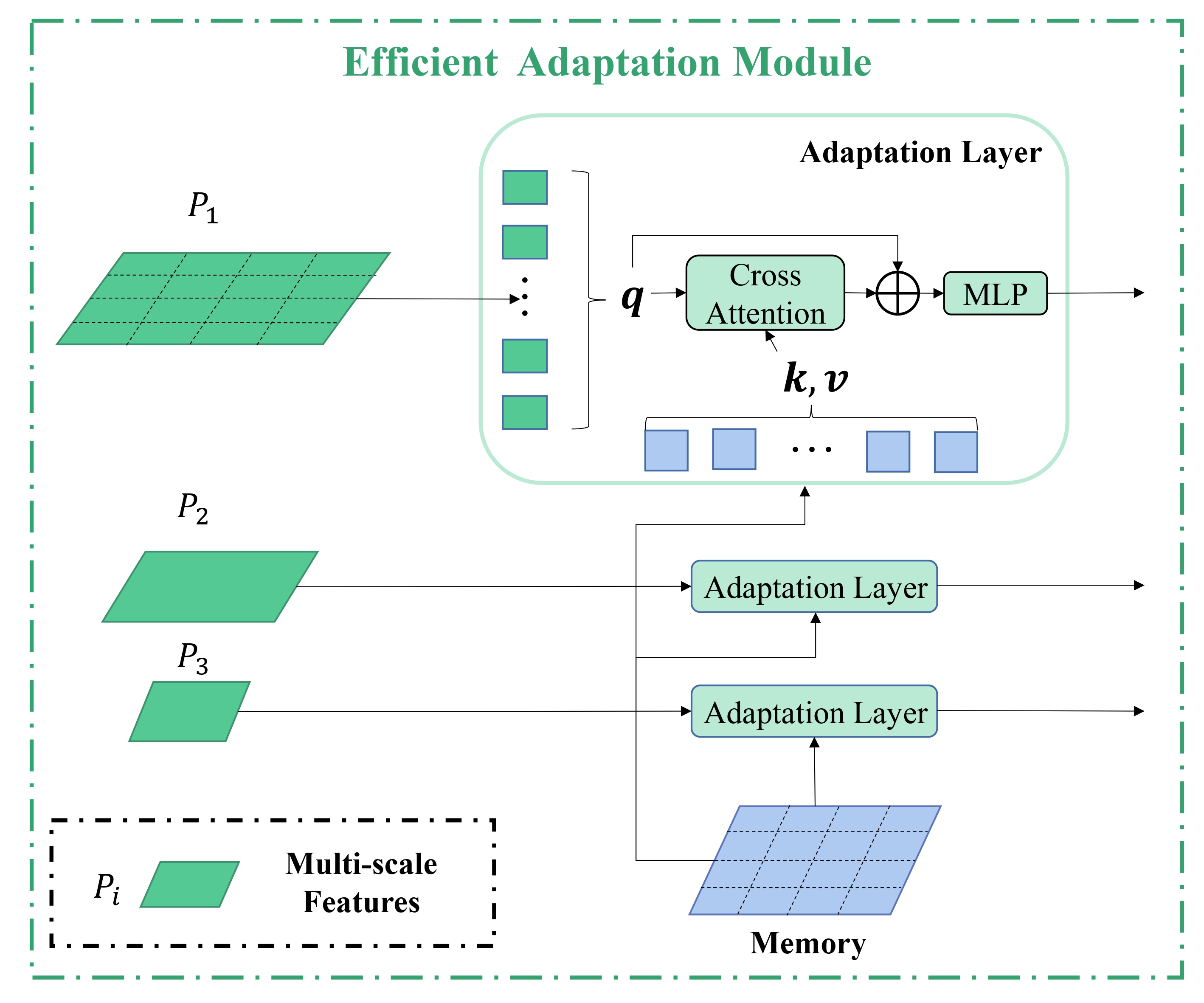
Overall pipeline. The proposed MS2A consists of two core parts. In the memory storage module, we first use the source data to train a base detector (we use YOLOX in practice and name this process prior learning), and use the base detector to extract prior knowledge for both source data and unlabeled target data. The prior knowledge is refined through clustering and momentum updates and stored as memory. On the other hand, in the memory adaptation module, we introduce an efficient adaptation module, which utilizes the memory to align the source data with the target data adaptively.
Detection Results

Qualitative comparisons on public datasets C → F setting.

Qualitative comparisons on public datasets K → C setting.

Qualitative comparisons on public datasets S → C setting.

Quantitative results on Indus-S → Indus-T1.
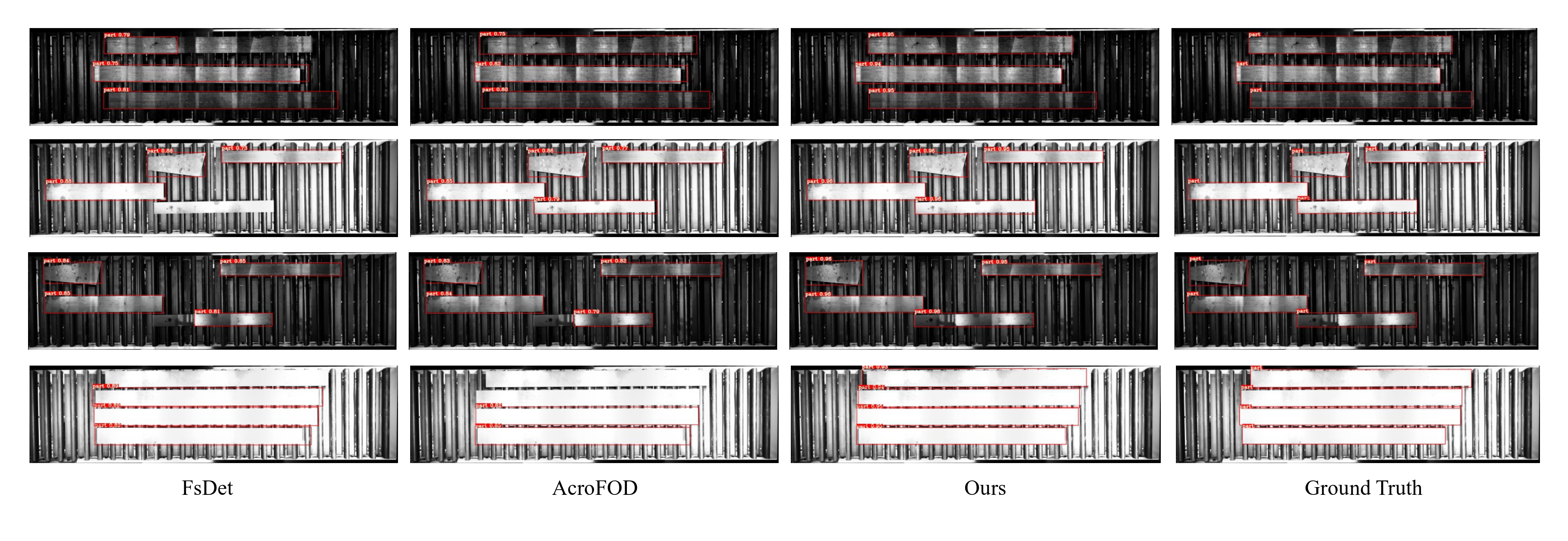
Quantitative results on Indus-S → Indus-T2.
Other Results

Comparisons between different datasets.

Feature maps visualization of target domain data.
BibTeX
Our code is coming soon!